Computer Vision in 2026: What Google, Apple and Meta Are Building


You look at a photo of a dog in a park. Instantly — the dog, the grass, the trees, the sky. You know what's close and what's far.
A computer sees none of that. Just a grid of millions of numbers. No dog. No park. Just numbers.
Computer vision bridges that gap. And in 2026, it's moving faster than ever.

What Can Computer Vision Do Today?
Capability | In Plain English | You've Already Seen It In... |
Image Classification | "What is this picture?" | Google Photos tagging your beach photos |
Object Detection | "Where are things, and what are they?" | Self-driving cars spotting pedestrians |
Segmentation | "Outline every object, pixel by pixel" | iPhone Portrait Mode |
Depth Estimation | "How far away is everything?" | AR furniture apps |
Image Generation | "Create a picture from words" | DALL-E, Midjourney |
Video Generation | "Create a video from words" | Google Veo |
3D Reconstruction | "Build a 3D model from regular photos" | Apple Spatial Scenes |
Three things made this possible: better architectures (Transformers), more internet data, and more computing power. Let's start with the architecture that changed everything.
How Computers "See": CNN vs Vision Transformer
For most of the 2010s, computers used CNNs — slide a tiny 3x3 pixel magnifying glass across the image, spotting local patterns. Edges first, then parts (eyes, wheels), then whole objects (faces, cars). It worked, but that tiny magnifying glass meant the network could only see local patterns. Connecting distant parts of an image was hard.
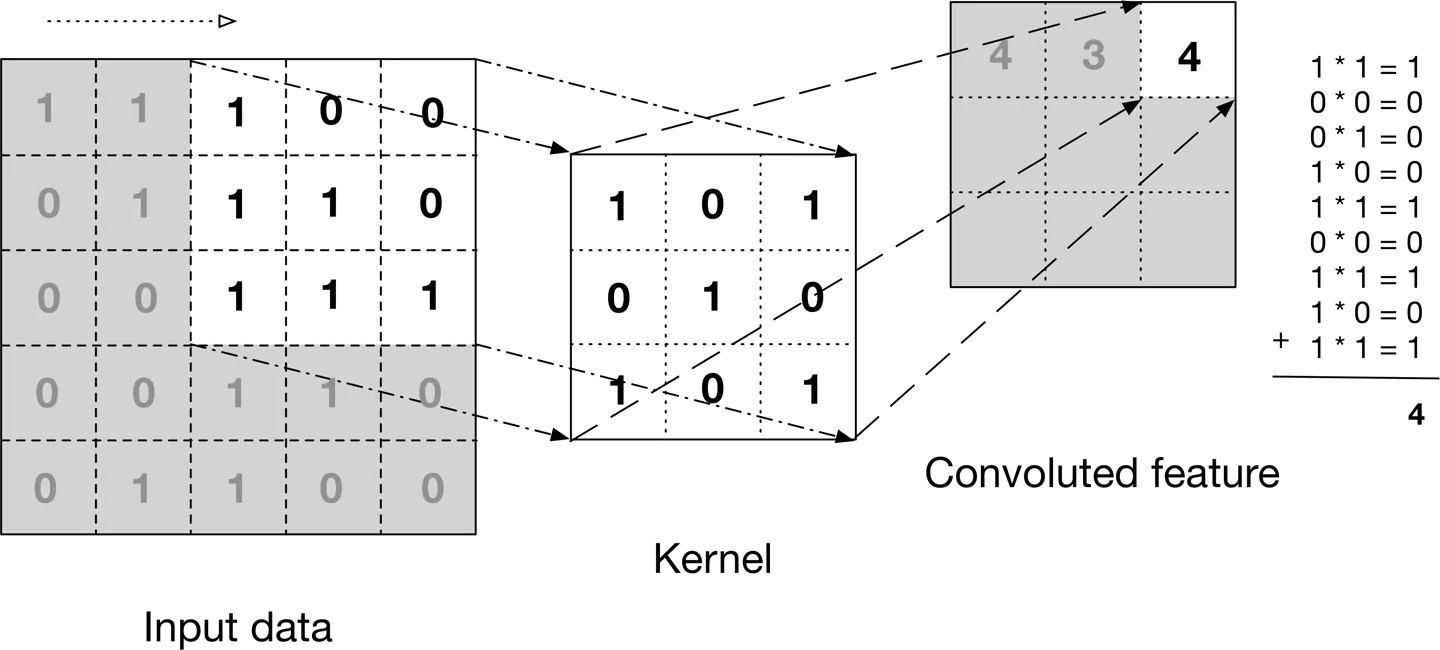
In 2020, the Vision Transformer (ViT) changed everything. Instead of scanning pixel by pixel, it chops the image into patches and lets every patch talk to every other patch simultaneously using "self-attention." A patch showing an eye can directly attend to a patch showing the other eye on the opposite side.
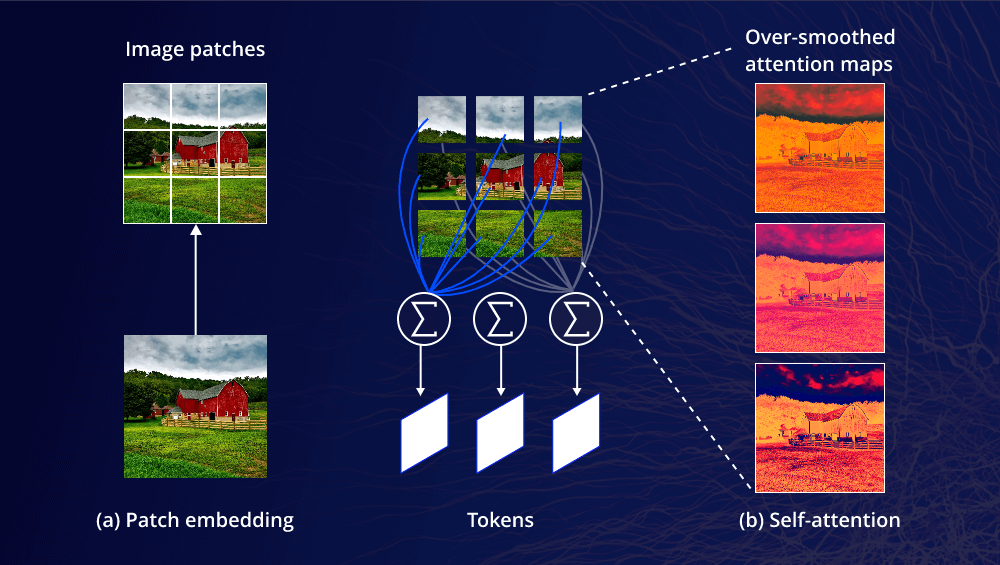
CNN = Reading a book through a keyhole, sliding line by line. You never see the whole page at once.
ViT = Laying the page on a table, seeing everything while focusing on any part.
ViT is now the backbone of almost every major vision system. All three companies have their own version:
Google: SigLIP 2 — powers Gemini's vision
Apple: AIMv2 — 89.5% accuracy on ImageNet, CVPR 2025 highlight
Meta: DINOv2 — learned to understand images without any human labels
That last one raises a question: how do you teach a model to see without telling it what anything is?
Teaching Without Labels
Traditional machine learning needs humans to label every image — "this is a dog," "this is a cat." Expensive, slow, doesn't scale.
Self-supervised learning lets models teach themselves from raw, unlabeled data. Three approaches:
"Same or Different?" — Take one image, create two distorted versions (crop, rotate, flip). The model learns they're the same image. Do this millions of times and it develops deep visual understanding.
"Teacher and Student" — A "teacher" model sees the full image; a "student" sees only a small crop. The student learns to match the teacher. When Meta trained a ViT this way (DINO), something remarkable happened: the model's attention maps perfectly outlined objects — even though nobody ever told it what objects are. It discovered the concept on its own.
"Fill in the Blank" — Hide 75% of an image's patches. The model predicts what's missing. To do this well, it has to understand the scene — if it sees a wheel and part of a road, the hidden part is probably the rest of a car.
The result: models trained without labels often produce better features than labeled ones.
Connecting Pictures and Words: CLIP
What if a computer understood images and text in the same "space" — so a sunset photo and the words "a beautiful sunset" are recognized as the same thing?
CLIP (OpenAI, 2021) does exactly this. Two "brains" — one for images, one for text — both map their input into a shared space. Trained on 400 million image-text pairs, matching photos to their descriptions and pushing apart mismatches.
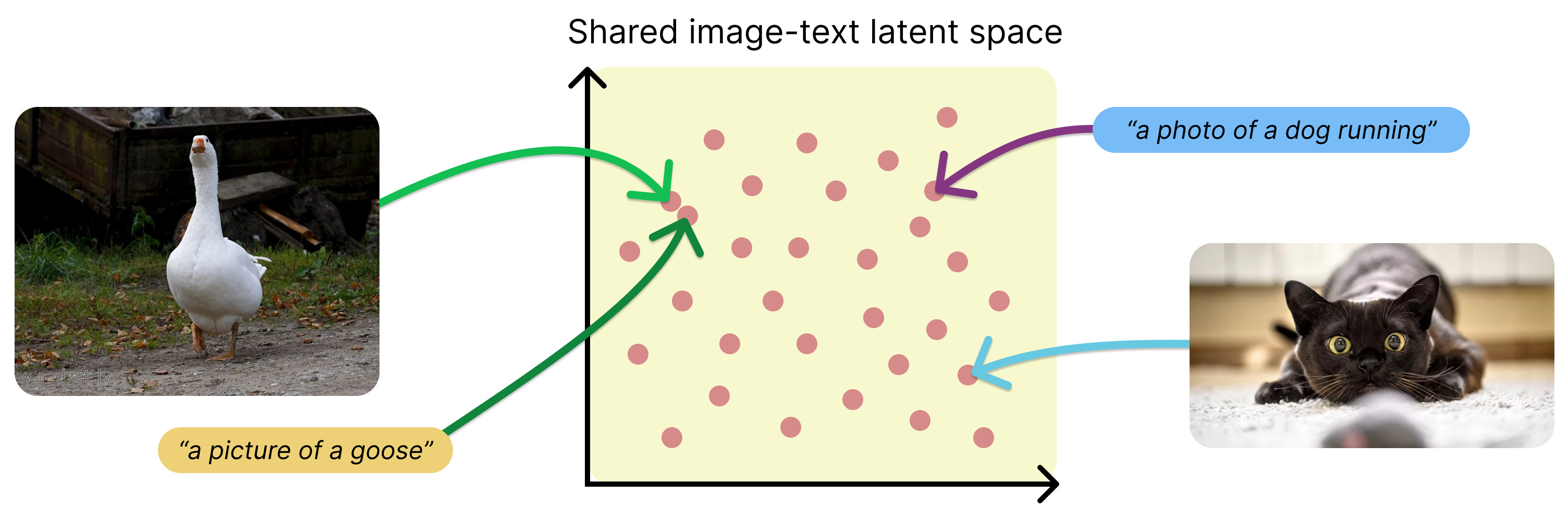
The killer feature: zero-shot recognition. Classify images into categories CLIP never trained on. Want to recognize mushroom species? Just write the names. No mushroom data needed.
CLIP is now a component inside Stable Diffusion, DALL-E, object detectors, and search engines. Google evolved it into SigLIP 2 (multilingual), Apple into MobileCLIP 2 (3-15ms on iPhone), and Meta into ImageBind (understands audio, depth, and thermal data too — a chainsaw sound retrieves lumberjack images).
What Gets Built on Top
Segmentation: The SAM Revolution

Meta's Segment Anything Model (SAM) transformed segmentation. Give it an image and a prompt — a click, a box, or text — and it produces pixel-perfect outlines. Trained on 1 billion masks across 11 million images.
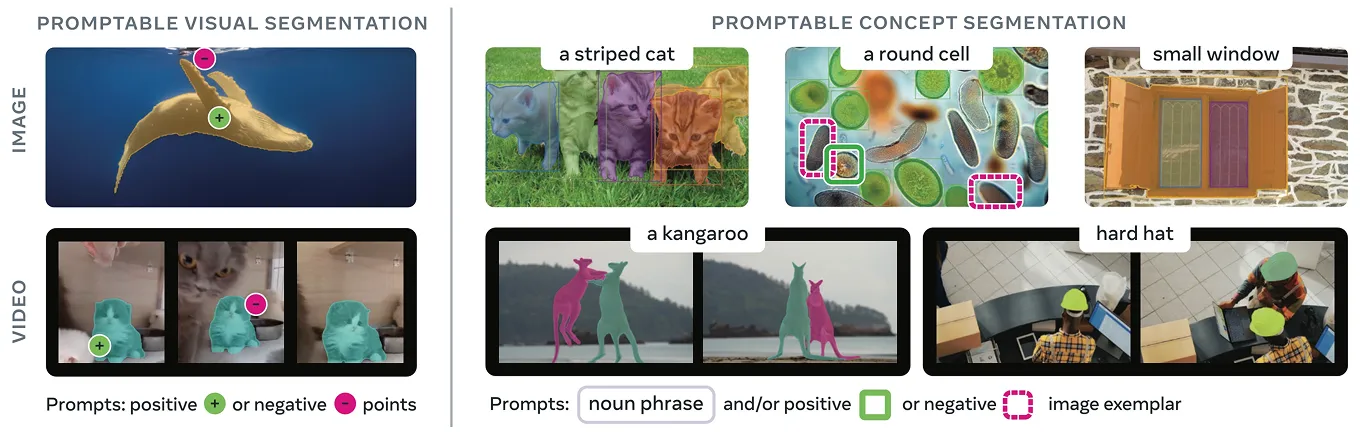
SAM 1 (2023): Click on an image, get instant segmentation
SAM 2 (2024): Works on video — click in frame 1, tracked through the whole video
SAM 3 (Nov 2025): Text prompts — type "yellow school bus," every bus gets segmented. Also does 3D
Depth Estimation
Your phone already uses this for Portrait Mode blur. But the 2024-2025 breakthrough is metric depth — actual distances in meters — from any single photo, without knowing what camera took it.

Apple's Depth Pro does this in 0.3 seconds. Meta's Sapiens is specialized for human bodies (+22.4% accuracy, trained on 300M images). This powers AR apps, 3D photos, self-driving cars, and robotics.
Image & Video Generation
Diffusion models power this. The core idea: take a clear photo, gradually add noise until only static remains. Train a network to reverse this — start from noise, denoise step by step, and a realistic image emerges.

An efficiency trick called Latent Diffusion compresses images 48x before denoising — this is what made Stable Diffusion possible on consumer hardware.
Imagen 4 (Google): 10x faster, best text rendering in generated images
Emu 3.5 (Meta): Powers Instagram AI stickers, 4-7 seconds
Veo 3.1 (Google): 60-second videos in 4K with audio
Movie Gen (Meta): Your face + text prompt = personalized video. Outperformed Sora
Building 3D From Photos
3D Gaussian Splatting is winning: represent scenes as millions of tiny colored blobs with position, shape, and transparency. Rendering is just projecting blobs onto a screen — exactly what GPUs do. Result: 100+ FPS, real-time, VR-ready.
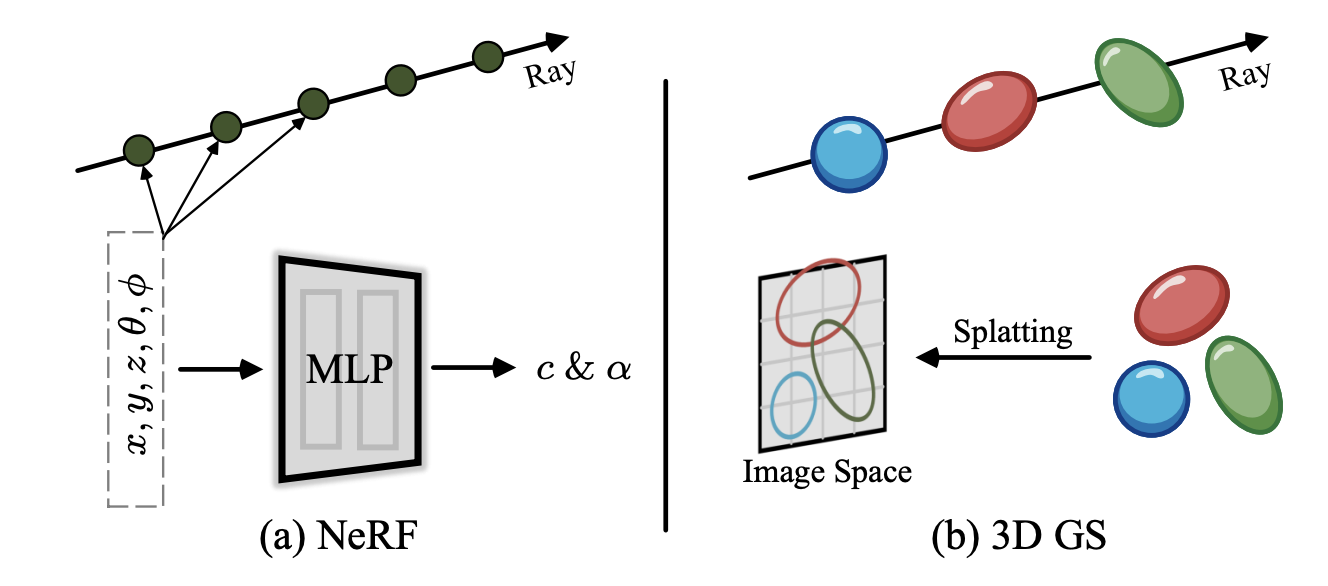
You don't even need photos anymore. Google's DreamFusion pioneered text-to-3D: start with random 3D points, render them, ask an image generator "how would you make this look like 'a steampunk robot'?", use the feedback to adjust, repeat thousands of times. A correct 3D model emerges — no 3D training data needed.
SHARP (Apple): Single photo to 3D in under 1 second. Powers iOS 26 Spatial Scenes
Meta 3D Gen: Text to 3D with realistic materials. 72% preferred over competitors
The Frontier: Point Tracking & World Models
Point tracking follows an exact pixel through every frame of a video — even through occlusions. Meta's CoTracker tracks all points jointly (not independently), maintaining accuracy over long videos. Google's TAPIR does 256 points at 40 FPS.
World models are the bleeding edge. Google's Genie 3 generates navigable 3D environments from text at 24 FPS — walk around, interact, modify mid-session. SIMA 2 is an AI agent that lives inside these worlds and completes tasks. Meta's V-JEPA 2-AC learns physics from video and controls robot arms with under 62 hours of training data.
Specialized Applications Worth Knowing
MedGemma (Google): Reads X-rays, CT scans, pathology slides. 81% of its chest X-ray reports judged "sufficient" by radiologists. Deployed in hospitals in Taiwan and Malaysia.
Sapiens (Meta): 308 body keypoints, body part segmentation, human depth. Trained on 300M human images.
FireSat (Google): Satellite constellation detecting fires as small as 5x5 meters — 400x better than existing satellites.
SynthID (Google): Invisible watermarks on AI-generated content. 10B+ items watermarked. Survives cropping and compression.
Who's Winning Where?
Domain | Leader | Why |
Segmentation | Meta (SAM 3) | Images, video, text prompts, and 3D |
Image Generation | Google (Imagen 4) | Fastest, best text rendering |
Video Generation | Google (Veo 3.1) | 4K, 60s, with audio |
On-Device AI | Apple (FastVLM) | 85x faster on iPhone |
Depth Estimation | Apple (Depth Pro) | Metric depth in 0.3s |
3D From One Photo | Apple (SHARP) | Under 1 second |
World Models | Google (Genie 3) | First real-time interactive worlds |
Medical Vision | Google (MedGemma) | Deployed in hospitals |
Human Body | Meta (Sapiens) | Only dedicated model for this |
Open-Source | Meta | Most open overall |
Google leads in cloud models and generation. Apple leads in on-device efficiency and 3D. Meta leads in open-source and foundational vision models.
Where This Is All Going
One model does everything. Single foundation models (DINOv2, SigLIP 2) handle classification, detection, segmentation, and depth — no separate model per task.
No labels required. Train on billions of images without human annotation. Build niche apps without collecting labeled datasets.
3D is instant. Single photo to 3D model in under 1 second. Every photo can become a 3D experience.
Vision AI runs on your phone. Real-time, offline, private. No cloud costs.
From seeing to acting. AI that doesn't just describe what it sees — it navigates, manipulates, and interacts with visual environments.
Based on a research deep-dive and presentation at The Noughty Fox. All models and capabilities are publicly documented as of February 2026.